인터페이스를 한 단어로 표현하면 '규약'이다. 개발하면서 꼭 지켜야 할 '규약'같은 존재로, 바꿔말하면 개발할 때 반드시 포함해야하는 멤버를 모아놓은것이 인터페이스다. 이렇게 말하면, 추상 클래스와 다른점이 무엇인지 헷갈릴 수 있다. 추상 클래스는 쉽게 말해 개발이 들어간 시점에서 공통된 속성을 모아놓은 클래스이며, 해당 추상 클래스를 '상속'하는 클래스는 해당 추상 메소드들을 모두 구현하여야 한다. 인터페이스는 이와 다르게 개발이 들어가기 전에 만들어질 메소드들에 대해 '규칙'을 정해놓은 것이고, 이를 '구현'하는 클래스들은 해당 메소드들을 모두 내용을 담아 만들어야 한다.
규칙? 그게 뭔데?
아직까지 이해가 안되는가? 그렇다면 경우를 들어 설명해 보자면, A와 B가 함께 자동차 객체를 생성하는 클래스를 만든다고 하자. 이 때, A는 자동차의 구동을 담당하고, B는 자동차의 프레임을 담당한다고 하자. 결국 자동차는 프레임과 구동부가 결합되어야 하는데, 만약 결합부가 일치하지 않는다면 설계에 실패했다고 볼 수 있고, 즉 자동차 객체를 생성 못한다고 볼 수 있다. 이를 위해 결합부에 대해 어떻게 설계하겠다는 약속을 정해야 하는데, 이를 인터페이스를 이용해 약속하는 것이다.
인터페이스 생김새
인터페이스는 이렇게 생겼다.
interface CarInterface{
public void move();
public void setSpeed(int speed);
}
CarInterface는 move와 setSpeed에 대해 설계 방식을 정하고 있고, 해당 인터페이스를 구현하는 클래스들은 두 함수에 대해 실질적인 내용을 담아야한다. 즉, 인터페이스는 함수내부가 어떻게 생겼을 지 모르겠지만, return 타입, 받아들일 파라미터 등 함수가 어떻게 생겼는지를 정해놓은 것이다. 따라서 A와 B가 같은 자동차를 설계하기 전에 인터페이스를 만들어 놓고, 결합부에 대해 약속을 정한다면 결합부가 일치하지 않아 자동차를 만들 수 없는 일은 발생하지 않을것이다.
왜 하필 인터페이스? 추상 클래스로는 안돼?
인터페이스가 가지는 추상클래스와의 가장 큰 다른점은 재사용성이다. 클래스는 다중상속이 불가능하지만, 인터페이스는 다중상속이 가능하다.
interface Vehicle{
public void move();
}
interface WheelObjects{
public void setWheels();
public void getWheels();
}
interface Car extends Vehicle, WheelObjects{
public void setHorsePower(float horsePower);
}
interface Airplane extends Vehicle{
public void setMaha(float Maha);
}
위와 같은 다중상속이 가능해짐으로써, Car라는 인터페이스를 만들기 위해 Vehicle과 WheelObjects의 인터페이스를 상속받아 각 인터페이스가 갖는 규칙을 모두 가질 수 있는 것이다. 뿐만 아니라, Vehicle 인터페이스를 Car에만 사용하는 것이 아니라 Airplane이라는 움직이는 방법이 전혀 다른 이동수단이 상속받을 수 있게 설계할 수 있다. 만약 추상클래스였다면, Car가 갖는 속성들을 Airplane은 가질수 없는게 당연한것과는 반대되는 성질이다. Java 8이 넘어가면서 추상클래스와 인터페이스의 관계는 많이 모호해지긴 했지만, 인터페이스의 특징을 잘 살리면 인터페이스 나름의 이용성이 큰 녀석이기 때문에 잘 이해해두면 좋은 친구다.
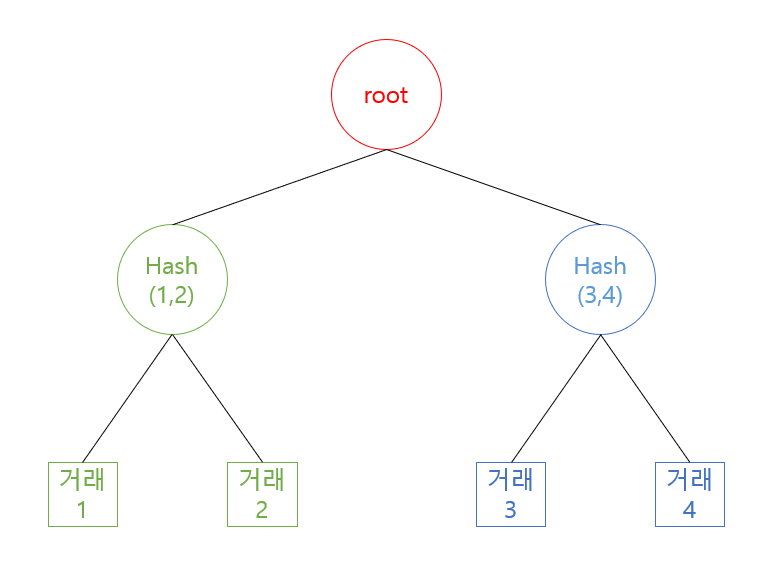
블록체인의 작업증명은 거래(트랜잭션)이 주어지면, 해당 거래를 가지고 블록을 만들 수 있는지 확인해야 한다. 주어진 거래와 같은 블록을 이루는 거래들을 이용하여 해당 블록의 Hash값과 일치하는지 확인해야 하는데, 이 때 머클트리를 활용한다.
머클트리
머클트리는 위 이미지와 같이 생겼는데, 거래 정보는 Leaf Nodes를 구성하고, 해당 거래 정보의 부모들은 각 자식들을 Hash 한 값이 된다. 이렇게 쭉쭉 타고 올라가 결국 root값 또한 root의 자식들을 hash한 값으로 이루어진다. 또한 Merkle Tree는 생성된 후에 값이 변조되면 안되기 때문에, 오직 getRoot()라는 method만 가진다. (블록체인에서 블록의 수정은 불가능하기 때문이다.) Merkle Tree를 정말 트리로 구성하여 삽입, 수정, 삭제 등의 기능을 구현해도 되지만, 이는 Java의 자료구조에서 다룰 것이고, 오늘은 블록체인의 Merkle Tree이기 때문에 단순 삽입을 통한 merkle Tree를 구성하게 하겠다.
블록으로 만들려고 하는 상황중 가장 좋은 경우는 트랜잭션의 갯수가 2^n꼴로, 이진트리를 만들었을 때 모든 leaf노드들을 트랜잭션으로 만들 수 있을때는 가장 편하다. 받아들인 트랜잭션(거래)들을 모두 leaf 노드로 설정하고, 부모를 만들어 나가며 root값을 찾으면 되기 때문이다.
거래의 수가 홀수라면 어떻게?
내가 가지고 있는 홀수 개의 수로 머클트리를 만들어야 할때는, 간단하게 다음과 같이 해결할 수 있다.
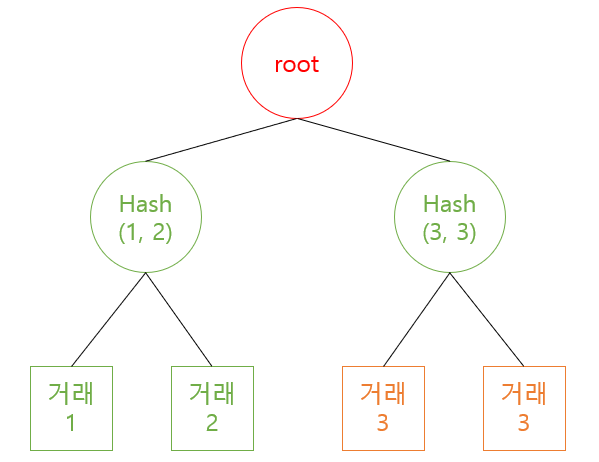
짝이 없는 거래(마지막 홀수번째)는 자신을 이용하여 해쉬한다.
짝이 없는 거래, 마지막 홀수번째 거래의 경우에는 자기 자신을 한번 더 사용하여 해시값을 만들면 된다. 이 아이디어를 응용해 보면, 2^n꼴이 아닌, 짝수개의 트랜잭션은 어떻게 하면 될까? 다음 그림을 보고 힌트를 찾길 바란다.
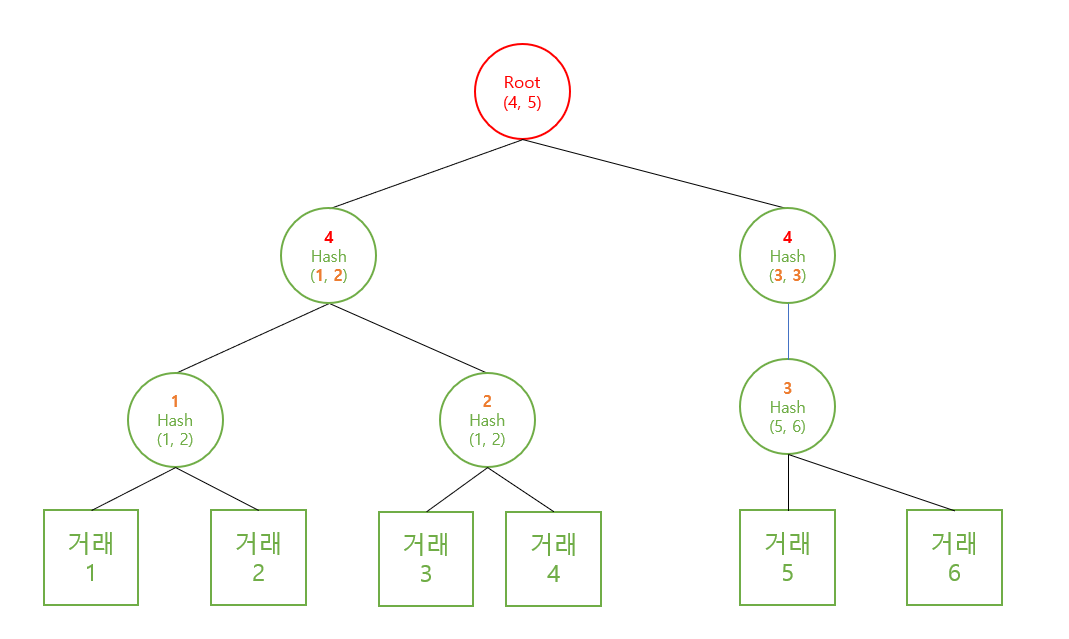
짝수개 머클트리
그림상 2번 Hash가 (1, 2)라 되어 있는데 오타다. Hash(3, 4)가 2번 동그라미가 되어야 한다.
머클트리 구현 아이디어
머클트리는 Binary Tree형 자료구조이다. 그리고 실제 데이터 삽입은 단말 노드에서만 이루어진다. 즉 머클트리는 기존 트리처럼 Top-Down 형식의 구현이 아니라 Bottom-Up 형식으로 구현하면 된다. 그리고 블록체인의 각 블록은 머클트리의 루트값만 가지고 있으면 된다. 바꿔 생각해보면, 만약 블록체인이 머클트리를 이루는 모든 해쉬값을 갖고 있으면 추적할 수 있게 되는것이고, 이는 보안상 구멍이 될 수 있는 것이다. 누구든 해당 블록을 만드는 각 트랜잭션을 만들 수 있게 되고, 그를 바탕으로 누가 어떤 거래를 했는지 알 수 있게 되는 것이다. 따라서 머클트리는 각 depth간 모든 해쉬 정보를 갖고 있을 필요가 없으며, 머클트리를 검증하기 위한 각 계층의 해쉬값을 Peer들에게 요청하면 되는것이다. 다시 본론으로 돌아와서 머클트리는 따라서 Root값만 가지고 있으면 된다. 그렇기 때문에 Tree의 모든 특성을 반드시 갖고 있어야 하는것은 아니다. Bottom-Up 구현을 따라서 ArrayList를 이용해 구현해 볼 것이다.
위 사진을 보고 어느정도 이해가 가는가?
머클트리와 관련하여 어떻게 머클트리가 생겼는지 알 수 있지만, 실제로 구현하는데에는 어려움이 있을 수 있다. 이전에 작성한 ArrayList와 마찬가지로 기본 아이디어만 본 포스트에서 구현하고, 활용과 응용은 직접 하시길 바란다.
위 이미지를 보면 알겠지만, ArrayList에 거래를 집어 넣고, 2개씩 끊어 Hash를 진행하면 된다. 함수 하나로 서론에서 말한 세가지 경우를 모두 처리하는 코드를 만들 수 있지만, 세 방향 모두 나눠서 진행할 것이다. 우선 완벽히 Full Binary Tree를 이룰 수 있을때에 대한 구현 방법이다. 이 경우는 정말 쉬운데, 아래 사진에서 처럼 두개 씩 끊어 Hash를 진행하고, List의 가장 마지막에 오는 녀석이 머클트리의 Root 값이 된다.
본 코드는 정말 "아이디어의 기초"를 표현하기 위한 코드이다. depth를 구해서 얼마만큼 Hash를 진행하여야 머클트리가 완성되는지를 표현하였다. depth를 다른시각으로 보면 level이 되고, level만큼 부모를 만들어야 root가 되는지 알 수 있기 때문이다. (이진 트리는 log2n 만큼의 depth를 갖고, 따라서 getDepth 함수는 정말 수학식을 나타낸 것이다.) i가 depth부터 시작하는 이유는 bottomUp 이기 때문에, 아래에서부터 위로 만들기 위함이다. j는 현재 내가 만들고 있는 List의 사이즈를 2^depth로 나누었을때 나머지인데, 그 이유는 다음과 같다.
총 depth가 4인 트리에서, depth 2에 대해 만들기 시작했을 때, depth 3에는 데이터가 8개 존재한다.
또한 hash를 시작해야 하는 List의 인덱스는 0인데, 그 이유는 List에는 방금 막 만든 해시값들만 담겨있기 때문이다. Depth 2에 대해서 해시가 모두 끝났으면, depth 1로 올라오게 되고, 이 때 hash를 시작해야 하는 인덱스는 9이다. 이 때 List의 사이즈는 12이고, i는 2(최초 depth는 4이고, i가 2번 반복했다. 따라서 4-2=2)가 된다.
즉 12 % 4 = 8이 되고, 0~8에 존재하는 원소는 9개이기 때문에 우리가 찾고자하는 인덱스 9가 된다.
for(int j~) 부분을 보게되면, 우리가 만든 List에서 해당하는 index에 대해 Hash를 진행하고 있는것을 확인할 수 있다. if(i == 1)인 부분은, i가 1, 즉 root의 자식 노드들이 되고, 따라서 hash를 진행할 때 size -2, size -1을 통해 마지막 두 Hash값에 대해 Hash를 진행하면 Root 값이 나오게 된다.
거래가 홀수개
private String createOddRoot(ArrayList<MerkleNode<Object>> merkleNodes) { int size = 0; int depth = getDepth(merkleNodes.size())+1; System.out.println("depth: " + depth); ArrayList<String> datas = new ArrayList<String>(); datas.clear(); int start = 0; int last = merkleNodes.size(); for(int i = depth; i > 0; i--) { start = (i == depth || (i == depth-1) ? 0 : last); last = (i == depth ? merkleNodes.size() : datas.size()); for(int j = start; j < last; j += 2) { if(i == depth) { datas.add( new Crypto().doHash(merkleNodes.get(j).getData().toString() + merkleNodes.get(( (j==last-1 ? (j) : (j+1)) )).getData().toString()) ); } else { datas.add( new Crypto().doHash(datas.get(j) + datas.get( (j==last-1 ? (j) : (j+1)) )) ); } } } size = datas.size(); return datas.get(size-1); }
거래가 홀수일 때는 j의 반복자 시작과 마지막을 잘 설정해주면 된다. 홀수개에 대하여 시작 부분은 최초 트랜잭션을 받아오는 부분과, 그 다음 부분은 모두 0부터 시작하면 된다. 그 이유는 최초 List가 비어있고, 전달받은 거래들에서 데이터를 가져오기 때문이고, 최초 부모들을 만들기 성공했다면, 우리가 만든 List의 0번부터 해시를 진행해야 하기 때문이다. 그 이외의 경우에는 이전 반복자의 last값이 시작값이 되는데, 해시를 시작해야하는 인덱스 번호가 곧 지난번의 마지막 인덱스 이후이기 때문이다. 또한 해당하는 인덱스의 값은 이전 반복자에서 분명히 만들어 졌기 때문에, 이렇게 사용할 수 있는 것이다. last의 경우, 최초에는 내가 가지고 있는 거래의 수 만큼 해시를 진행해야하고, 그게 아니라면 만들어진 List의 사이즈만큼 만들어야 하기 때문이다. 중요한것은, Hash를 만들 때, 원소가 한개이냐(마지막 홀수번째 원소)만 확인하면 된다. 만약 그렇다면, 본인을 한번 더 사용하면 된다.
머클트리는 생각보다 간단하지만, 간단한 만큼 자료가 많지 않아서 어떻게 접근해야 할까 고민하는 사람이 많은 것 같다. 따라서 본 게시글에서는 머클트리는 이루는 기초적인 방향과 이를 바탕으로 한 기초적인 방법을 다루어봤다. Full Binary Tree가 아닌 짝수 개를 갖는 코드는 위에서 준 힌트와 Odd를 확인해보면 쉽게 만들 수 있다.\ 머클트리를 만드는 자세한 방법은 JAVA에서 다루도록 하겠다.
정의된 RESTful API를 구현하는 도중 Client측에서 요청한 정보에 대해 결과를 모두 반환하지 않고 중간에 글자가 잘리는 버그가 있었다.
중간에 메시지가 잘린다.
해당 버그를 해결하지 않은 시점에서 본 게시글을 작성하기 시작했는데, 버그는 쉽게 해결됐다.
버그의 발생은 라즈베리파이에서 MkWeb의 RESTful API를 사용할 경우 모두 출력되지 않고 종료되는 (성능상의 이슈로 인해) 문제가 있었는데, 해당 문제를 해결하기 위해 PrintWriter의 버퍼를 일정 주기를 내가 강제하여 flush 하였더니, 기존에 잘 동작하던 플랫폼에서도 해당 이슈가 발생하였다.
flush를 지워봐도 해당 문제가 지속되어, flush를 내장하고 있는 PrintWriter의 close() 메소드를 사용해보니 이유는 모르겠지만 기존 플랫폼에서는 버그가 해결됐다.
왜 잘 나오는거지?
아무리 생각해봐도 flush를 강제적으로 해주면, 성능 저하의 이슈가 발생할지라도 정상적으로 출력돼야 하는데 잘 모르겠다.
해당 문제의 원인을 알아내면 이어쓰도록 하겠다.
2021/01/07 21:32분 수정
오류의 원인을 발견하였다. HttpServletResponse 객체의 헤더 중 Content-Length를 직접 설정해 주었는데, 이로 인해 response의 PrintWriter 객체가 내가 Content-Length를 설정한 만큼만 출력하게 되어 있었다. 따라서 실제 출력하고자 하는 내용이 모두 출력되지 않는 버그가 간간히 있었다.
RESTful API PUT method를 어떻게 구현할지 많이 고민 했다. RESTful API에 대한 정보를 찾아봐도, 특성만 나타나 있지 실제로 어떤식으로 구현해야할지는 없었다.
MkWeb의 초기 버전은 RESTful API의 성능을 떠나서 "동작하는 기능"으로써의 구현을 진행하고 있기 때문에, 개발 및 테스트 하면서 원리를 이해하고, 앞으로의 수정방향을 잡고 있기 때문에 일단 구현해 봤다.
MkWeb에서 PUT Method는 다음과 같이 정의 하였다.
삽입 / 수정, 즉 UPDATE를 담당하는 METHOD
PUT Method에 관한 응답 및 처리를 찾아 봤을 때, 어떤 글은 GET과 같은 조회와 POST의 삽입의 기능을 담당한다.
또 어떤 글은 POST의 삽입 기능과 SQL의 UPDATE문을 담당한다는 등 크게 두 파로 나뉘어 있었다.
그래서 사실 조회의 경우 URL을 통해 쉽게 할 수 있으니, 삽입과 수정의 기능을 바탕으로 만들었다.
그리고 수정의 경우, PATCH로써 동작하게끔 했다. ( PATCH 를 넣으니, 톰캣의 버전 때문인지 정상적인 method가 아니라며 실행되지 않았기 때문. 후에 가능하다면 MKWeb을 업데이트 할 때 PATCH를 새로 만들 예정이다.)
조회와 삽입을 구분하는 기준은 다음과 같이 정했다.
URI에 수정하고자 하는 대상의 조건을 보내고, Body Parameter에 수정 내용을 입력한다. 이 때, 대상이 존재하지 않으면 삽입, 존재하면 데이터를 수정한다.
이렇게 정의하고 나니 한결 쉬워졌는데, 데이터 입력 및 수정 할 때, 삽입/수정하고자 하는 column이 Not Null이고 Deafult 값이 없거나 하는 경우에는 오류가 발생해서 난감했다.
사실 이 문제는 RESTful API의 본질적인 기능을 잊고, 기능 구현에 집중하다보니 발생한 문제였는데, message와 error code를 보내주는걸로 해결했다.
사용 예는 다음과 같다.
URI : /users/name/dev.whoan body parameter: email=dev.whoan@gmail.com
users Data Set에서 name column이 dev.whoan인 사람의 email을 dev.whoan@gmail.com으로 수정한다. 여기에 입력되지 않은 column은 기존 값을 유지한다.
삽입 URI: /users/name/whoan body parameter: email=dev.whoan@gmail.com, name=whoan
users Data Set에 name=whoan이라는 사람이 존재하지 않으면, email=dev.whoan@gmail.com, name=whoan으로 데이터를 삽입한다. 이 때, 모든 column이 입력되어야 한다. 모든 column이 없으면, 400 Bad Request와 모두 입력하라는 message를 보내주었다.
구현할 때 문제점이 있었는데, MkWeb의 SQL을 정의하는 구간에서 각 data를 짜집어 SQL을 미리 정의해두는게 있었는데, 이 때 이미 SQL이 설정되어 있어서 따로 수정할 수 없는게 문제였다. 이는 따로 RESTful API전용 SQL Creator를 만들어 고쳤다. (여기서 중요한건 이게 아니니 패스)
Data의 유/무를 확인하기 위해 GET Method를 통해 PUT Method 요청시 특정된 데이터가 존재하는지 확인했고, 특정된 데이터가 있다면 update, 없으면 insert문을 수행하게 했다. 사실 insert문의 경우 POST로 대체할 수 있지 않을까 싶었는데, PATCH의 기능을 수행하게 하였기 때문에 column의 값들이 문제가 되어서 put에서 수행하게 했다.
그리고 PUT method 안에서 INSERT와 UPDATE 중 하나가 발생하기 때문에(두 메소드 모두 사용되기 때문에), 해당 작업 수행 후 MkRestApiResponse에 응답 코드를 담아서 반환해주었다.
프론트로부터 request.getParameter를 통해 데이터를 받을 때, 데이터가 없는 경우가 있다. 이 때는 Form Data나 Body Message에 데이터가 담겨온 것인데, 이럴 경우 Stream을 이용해 parameter를 받아와야 한다. 보통 프론트 사이드에서 HttpRequest에 Parameter를 전송할 경우 Servlet에서 다음 함수로 받을 수 있다.
파라미터명을 아는 경우 request.grtParamrter(String param); 파라미터명을 모르는 경우 request.getParameterNames()
위 방식은 쿼리 스트링, 혹은 Form Data의 경우 정상적으로 받아지지만 Content-Type이 변하여(application/json 등) Body Content에 parameter가 담겨올 경우, 위 방식으로 Parameter를 찾아보면 null 값이 나온다.
이럴 경우 body content를 읽어들여야 하는데, request.getInputStream()을 이용해 buffer를 읽어들이면 된다.
인터넷 연결이 오락가락 해서 문제를 찾아보니 7년동안 사용한 아이피타임 A1004가 보내달라고 소리지르고 있는걸 확인했다.
무려 7년동안 잘 견뎌준 녀석이지만, 고통스러워하는 모습에 새로운 녀석을 장만했다.
"안테나는 4개여야 잘터진다!"라는 생각을 갖고 있었지만, 안테나가 3개임에도 불구하고 꽤 괜찮은 성능을 내는 녀석을 찾았으니, 바로 아이피타임 A6004MX다.
사실 성능도 있지만, 가격도 합리적이어야 하는데, 마침 이녀석이 세일하고 있길래 바로 구매했다.
A6004MX 박스가 굉장히 크다
장비를 개봉했을 때 들어있는 구성품은 다음과 같다.
기기 본체, 전원 아답터, 설치 설명서, 이지메시 사용 설명서
정면, 측면, 옆면, 후면
설치할 때 느낀건데, 정면 측면 후면 샷을 모두 뒤집어 놓고 찍었더라.
A6004MX 스펙은?
박스에 적힌 스펙이다.
Wi-Fi Mesh를 지원하여 여러개의 공유기(Wi-Fi Mesh 기술을 지원하는)를 하나의 네트워크로 묶을 수 있다. 특히 아이피타임의 경우 Easy Mesh기술을 통해 여러개의 네트워크를 하나로 쉽게 묶을 수 있다. 이를 통해 방마다 설치되어 있는 와이파이 공유기가 이름이 다른 경우, A 네트워크 사용중 B 네트워크로 자동연결되어 네트워크 끊김이 발생하거나, 더 느린 네트워크로 연결되어 답답함이 생길 수 있는데 이를 방지할 수 있다. 즉 끊김없는 네트워크 환경을 구성할 수 있다.
A6004MX의 무선랜 속도는 IEEE 802.11ac를 지원하여 2.4GHz 최대 600Mbps, 5GHz 최대 1300Mbps를 지원한다.
유선랜의 경우 최대 1Gbps까지 지원한다. 10Gbps이상의 속도를 사용하고자 하는 사람들은 더 높은 사양의 공유기를 사용해야 한다.
후면에 USB 3.0 포트가 있어, 해당 포트에 외장하드 등 데이터를 저장하고자 하는 저장장치를 연결하면 FTP 서버(파일서버)를 운영할 수 있게 되어있다. (해당포트에 휴대폰 충전 USB단자를 연결하면 충전기로도 사용할 수 있다!)
하드웨어 스펙의 경우 듀얼코어 1.25GHz, 128MB Ram을 지원하는데, 우리가 실사용하기에 큰 무리가 없는 사양이다. 나머지 스펙은 기존의 아이피타임과 같기 때문에 넘어가겠다.
실사용 환경
우리가 실제로 공유기를 고를 때는 얼마나 빠른가?만 고려한다. 추가적인 요소가 있다면, 아이피타임을 통해 웹서버를 구성할 수 있느냐? 인데, 후자의 경우 A6004MX를 통해 가능하다.
그래서 실제 사용환경에서 얼마나 빠른 속도가 나오는지 확인해 봤다.
스펙상에 나와있는 속도에 대해 쉽게 설명드리자면, 두 대역 모두 스펙상으로는 현재 통신3사에서 광고하는 5G보다 더 잘터지는 수준이다. 실제 사용 환경에서도 이런 속도가 나올 수 있는지 궁금했고, 더불어 아이피타임이 광고하는 MU-MIMO기술 (실제 사용 환경에서는 복수의 기기가 같은 네트워크를 할당받을 경우, 속도가 저하되는 문제를 방지)이 정말 동작하는지 직접 측정해 봤다.
테스트 장비
속도 측정을 위해 사용된 기기는 다음과 같다.
KT 기가 광랜 (1Gbps급)이며 통신사 공유기는 사용하지 않고 있다.
1. 무선랜
Galaxy Z Flip, Galaxy Tab S7+, LG Gram 2019 (단, 공유기에 붙어서 측정하는 경우는 없기에 공유기를 거실에 두고, 방에 들어와 측정하였다. 측정 거리는 공유기로부터 벽까지 2m, 그리고 벽 바로 건너편에서 측정하였다.)
2. 유선랜
인텔 CPU 데스크탑 + Cat 5E LAN Cable
우선 모바일기기에서 5G 측정이다.
모바일 기기의 경우 데이터 네트워크는 모두 '사용 안함' 상태에서 와이파이만 이용하였다. MU-MIMO기술이 있어서 속도 저하가 안될거라 예상하였지만, 실제는 그렇지 않았다.
S7+에 속도가 몰아졌다.
몇번을 시도 해도 Z Flip의 속도가 더 빠르거나, S7+에 속도가 몰아지는 등 두 기기 모두 300Mbps에 가까운 속도를 내는 경우는 없었다.
그래서 한 기기씩 측정해 보았는데, 다음과 같다.
1. Z Flip만 측정
Z Flip만 측정
2. S7+만 측정
S7+만 측정
양 기기간에 발생하는 최대속도 차이는 기기차이인 것 같다. Z Flip은 아무리 해도 330Mbps를 넘는 경우가 없었고, S7+는 최대 500Mbps까지 나왔다.
2.4GHz의 경우는 두 기기 모두 평균 다운로드: 60.3Mbps 업로드: 131Mbps로 측정됐다.
노트북 환경에서의 속도는 다음과 같았다.
1. 5G
무선랜 노트북 5G
2. 2.4G
노트북 2.4GHz
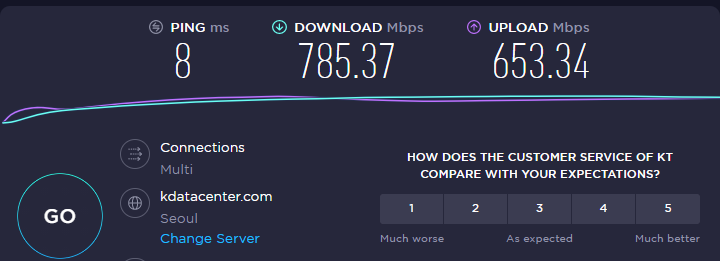
유선랜 측정
사실 데이터를 무제한 사용하는 입자에서 무선랜 보다 유선랜이 더 중요했다.
(요즘 LTE가 굉장히 느렸는데, 와이파이를 바꾼 후 집에서는 와이파이만 사용하고 있다.)
1차2차ㅊ3차
총 10번 시도 했을 때 평균 다운로드: 750Mbps 업로드: 625Mbps를 유지했다. 과거 1기가급 광랜이 많이 보급되지 않았을 때는 1.1Gbps도 나오곤 했는데, 보급이 많이 됨에 따라 속도가 많이 떨어졌다. (이건 KT에서 보상해야하는 것 아닌가?)
총평
총평을 내리자면, 잘 구매한 것 같다. 59,000원을 주고 구매했는데 해당 가성비가 꽤 괜찮다.
해당 기기를 사기 전에 아이피타임의 어떤 기기의 경우 DDNS를 여러개 지원하는데, 해당 기기는 타 보급품 급과 같이 1개만 지원하는건 안타까웠지만
Java는 클래스를 중심으로 객체들을 설계하는 언어이다. 바꿔 말하면 문제를 해결하기 위해 클래스를 설계하고, 이를 인스턴스화 하여 사용한다.
또한 Java를 사용할 때 의 장점 중(객체지향 프로그래밍의 장점 중) 재사용성이 있는데, 이는 다음과 같이 해석할 수도 있다.
'비슷한 형태를 묶어 하나의 클래스를 만들고, 그 클래스로부터 각각의 문제를 해결한다.'
즉, 클래스의 구현과 사용을 분리하여 만드는 것이 일반적이다. 만약 현대자동차를 만드는 클래스 하나, 기아자동차를 만드는 클래스 하나와 같이 같은 형태의 문제를 각각의 클래스를 만들면 낭비이고 비효율을 초래한다.
여기까지 이해하면 다음과 같이 설계할 수 있다.
class Car{
String company;
String name;
int speed;
Car(String company; String name, int speed){
this.company = company;
this.name = name;
this.speed = speed;
}
public void move(){
this.speed = 100;
System.out.println(this.company + "의 " + this.name + "가 " + this.speed + "의 속도로 달립니다.");
}
public void stop(){
this.speed = 0;
System.out.println(this.company + "의 " + this.name + "가 " + this.speed + "의 속도로 달립니다.");
}
}
<이는 정말 간단한 예를 표현하기 위한것이니 왜 이렇게 짰는지는 묻지 말아주길 바란다.>
그런데, 위에서 말했듯이, 클래스의 구현과 사용은 분리하는것이 좋다. 위의 예는 클래스의 '사용'을 나타낸 것이다.
이를 어떻게 구현과 사용으로 분리할 수 있을까?
구현은 Abstract(추상화) 사용은 Extends(상속)
abstract의 사전적 의미는 추상이다. 추상의 국어사전 속 의미는
추상1 (抽象)[명사][심리 ] 여러 가지 사물이나 개념에서 공통되는 특성이나 속성 따위를 추출하여 파악하는 작용. <출처: 네이버 국어사전>
이를 프로그래밍 관점에서 보자면, "객체들에 대해 공통적인 속성을 추상화 시켜놓고 해당 속성을 각각의 Class에서 구현하고 사용한다."로 생각하면 된다.
자동차로 예를 들면, 쉽게 자동차는 굴러가고, 멈춘다. 그런데 각각의 자동차가 어떤 속도로 굴러갈지, 어떻게 멈출지는 모르는 법이다. 따라서 위에서 만들었던 Car class에서 move와 stop을 추상화하면 된다.
Java에서 추상화 하는 방식은 abstract한정자를 사용하면 된다. 또한 abstract한정자를 갖는 클래스는 abstract class, 즉 추상 클래스가 된다.
우리는 각각의 자동차가 어떻게 굴러가는지, 또 어떻게 멈추는지 모른다. 즉 추상화하고자 하는 method의 동작 방식을 전혀 모른다. 따라서 abstract method는 본문 내용을 가져서는 안된다. 즉, 다음과 같이 표현하여야 한다
abstract public void move(); (단, 우리는 동작방식이 어떻게 될지 모르는거지, 인자로 뭐가 들어올지는 설정할 수 있다. 가령, 움직이는 속도를 전달받는다 하면 abstract public void move(int speed);와 같이 나타내면 된다.)
그러면 실제로는 어떻게 해야할까?
앞선 내용을 바탕으로 구현과 사용을 분리해 보면, 다음과 같이 나타낼 수 있다.
public abstract class CarFrame{
int speed;
String name;
String company;
abstract public void move();
abstract public void stop();
public void Status(){
System.out.println(this.company + "의 " + this.name + " 현재 속도: " + this.speed);
}
public int getSpeed() { return this.speed; }
public String getName() { return this.name; }
public String getCompany() { return this.company; }
public void setSpeed(int speed) { this.speed = speed; }
public void setName(String name) { this.name = name; }
public void setCompany(String company) { this.company = company; }
}
public class Car extends CarFrame{
public Car(String name, String company){
setSpeed(0);
setName(name);
setCompany(company);
}
public void move(){ setSpeed(100); }
public void stop(){ setSpeed(0); }
}
public class mainAbstract {
public static void main(String[] args) {
Car Sportage = new Car("스포티지", "기아자동차");
Car Tucson = new Car("투싼", "현대자동차");
Sportage.Status();
Tucson.Status();
/*****************************/
Sportage.move();
Tucson.move();
Sportage.Status();
Tucson.Status();
/*****************************/
Sportage.stop();
Tucson.stop();
Sportage.Status();
Tucson.Status();
}
}
CarFarme이라는 abstract class, 추상 클래스를 통해 자동차들에 대해 하나로 구현하였고, 각각의 자동차에 대해 Car라는 class를 인스턴스화 함으로써 사용하게 하였다. (이때 getter와 setter를 사용하지 않고 직접 변수 getter setter를 사용하고 싶으면 CarFrame의 변수들에 대해 접근제한자를 바꿔주면 된다.)
아래의 maniAbstract 클래스를 실행하면 다음과 같은 결과가 나온다.
move 이후에 속도가 100이 찍힌다.
앞에서 우리가 사용할 때 공통적인 내용을 추상화 했다. 프로그래밍을 시작한지 얼마 안된 사람이라면 다음과 같은 의문을 가질 수 있다.
"어? 그러면 쉐보레와 현대/기아가 있을때, 현대/기아만 갖는 속성은 어떻게 나타낼 수 있어요?"
우리는 현대 자동차와 기아 자동차가 같은 내용을 가진다고 가정 했다. (같은 그룹이라서..)
이는 우리가 Car를 상속받아 현대자동차 클래스 / 쉐보레 클래스를 각각 구현하여, 해당하는 클래스에 멤버변수나 메소드를 추가해주면 된다.
그러한 예를 나타내고 상속클래스 게시글을 마치겠다.
전방충돌감지 레이더를 장착한 기아 자동차의 스포티지와 깡통 옵션으로 출고된 트래버스를 구현할 때, 다음처럼 구현할 수 있다.
쉐보레를 싫어하는게 아니라 구현의 귀찮음으로 인해 스포티지만 전방인식 레이더가 있다고 구현했습니다.
public class Kia extends Car{
int frontObject = -1;
public Kia(String name, String company) { super(name, company); this.frontObject = -1;}
public void frontObject(int distance) {
this.frontObject = distance;
}
@Override
public void move() {
if(frontObject > 0) {
super.setSpeed(100 - frontObject);
}else {
super.setSpeed(100);
}
if(super.getSpeed() < 30) {
System.out.println("전방 충돌 주의!!! 긴급제동을 시작합니다.");
super.setSpeed(0);
}
}
}
public class Chevrolet extends Car{
public Chevrolet(String name, String company) { super(name, company); }
}
public class mainAbstract {
public static void main(String[] args) {
System.out.println("=====짧은머리 개발자=====");
Kia Sportage = new Kia("스포티지", "기아자동차");
Chevrolet Traverse = new Chevrolet("트래버스", "쉐보레");
Sportage.move();
Traverse.move();
Sportage.Status();
Traverse.Status();
System.out.println("===50m 전방 사람===");
Sportage.frontObject(50);
Sportage.move();
Sportage.Status();
System.out.println("===30m 전방 사람===");
Sportage.frontObject(70);
Sportage.move();
Sportage.Status();
System.out.println("===20m 전방 사람===");
Sportage.frontObject(80);
Sportage.move();
Sportage.Status();
}
}
Chevrolet Class는 frontObject라는게 없기 때문에 Traverse.frontObject를 사용할 수 없어서 Sportage에만 사용하였습니다.